我院蒋智威老师课题组在多模态视频理解技术方面取得新进展:(1)针对声音-视觉事件在视频中的定位任务,提出一种基于事件定位偏好学习的条件双分支范式,在事件定位与事件分类两个子任务之间建立条件依赖的关联关系,让事件定位能更充分地利用特定于事件类别的定位偏好,以获得更好的事件定位效果;(2)针对短视频排序任务,提出一种基于位置解码和后继预测的短视频排序框架,并精心构造了一个专门的短视频排序数据集,以促进新算法的开发和评估。
两项研究工作分别为:
1. Learning Event-Specific Localization Preferences for Audio-Visual Event Localization
声音-视觉事件定位(AVEL)旨在定位视频中可见且可听到的事件。现有的AVEL方法主要集中于学习适用于所有事件的通用定位模式。然而,事件通常会表现出模态偏好,例如视觉主导、音频主导或模态平衡,这可能导致不同的定位偏好。这些偏好可能被现有方法忽视,从而导致定位性能不够理想。为解决这一问题,该研究工作提出了一种新颖的事件感知定位范式,首先识别事件类别,然后利用特定事件的定位偏好来改进事件定位。为实现这一目标,该研究工作引入了一种基于记忆的度量学习框架,利用历史片段作为锚点来调整统一的表示空间,用于事件分类和事件定位。为了为这种度量学习提供足够的信息,该工作设计了一个空间-时间音视频融合编码器,以捕捉音频和视觉模态之间的空间和时间交互作用。在完全监督和弱监督设置下,该工作在公开的AVE数据集进行的大量实验,实验结果验证了该提出方法的有效性。
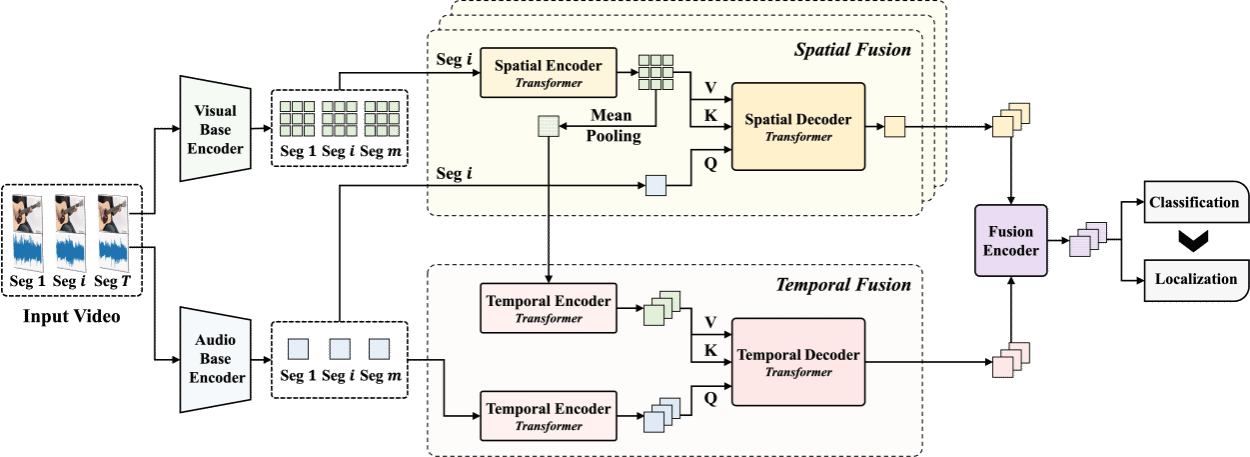
该研究工作相关成果《Learning Event-Specific Localization Preferences for Audio-Visual Event Localization》已在多模态处理顶级国际会议The 31st ACM International Conference on Multimedia(MM2023, CCF-A类会议)上发表,欢迎对该研究感兴趣的同学和学术同行来信交流:jzw@nju.edu.cn。
2. Short Video Ordering via Position Decoding and Successor Prediction
短视频集合是用户在各种在线短视频平台(如TikTok、YouTube、抖音和微信视频号)上浏览连贯内容的一种简便方式。这些集合涵盖了广泛的内容,包括在线课程、电视剧、电影和动画片等。然而,由于各种原因,如修订、二次创作、删除和重新发布,短视频创作者偶尔会以无组织的方式发布视频,这经常导致用户浏览体验不佳。因此,根据内容连贯性精确地对视频进行重新排序是一项至关重要的任务,可以增强用户体验,同时也是视频叙事推理领域中的一个有趣的研究问题。在这项工作中,蒋智威老师课题组为这个短视频排序任务精心构造了一个专门的多模态数据集,并介绍了一些基准方法在该数据集上的性能。此外,该工作还进一步提出了一个基于位置解码和后继预测的短视频排序框架。所提出的框架结合了成对和列表排序范式,可以摆脱成对范式中的二次增长和级联冲突问题,并提高现有列表方法的性能。大量实验证明,该提出方法在数据集上实现了最佳性能,并且框架的每个组件都有助于最终性能的提升。

该研究工作相关成果《Short Video Ordering via Position Decoding and Successor Prediction》已被信息检索领域顶级国际会议 The 47th International ACM SIGIR Conference on Research and Development in Information Retrieval(SIGIR2024, CCF-A类会议)长文录用,欢迎对该研究感兴趣的同学和学术同行来信交流:jzw@nju.edu.cn。


 English
English